Introducing BitShares Object Graph
Posted by Daniel Larimer on .As time progresses we gain a deeper understanding about the nature of block chain technology at both an economic and technological level. Today I would like to introduce the latest advancement in block chain technology: a graph database on a block chain.
Bitcoin introduced a new data structure called a block chain which is little more than a linked list of transactions where the inputs of every transaction link to the outputs of prior transactions. BitShares recognized that the structure of Bitcoin was too ridged and could be abstracted into a generic database with deterministic operations. Where as Bitcoin uses the term transaction in a purely financial sense, in the database world a transaction is a set of operations that must all complete without error or the database should be left unchanged.
There are many different types of databases that have been developed over the years. The most widely used databases today are called Relational databases and are normally interfaced with via SQL. Recently the “NoSQL” databases have become popular. NoSQL encompasses a wide variety of different database technologies that were developed in response to a rise in the volume of data stored about users, objects and products, the frequency in which this data is accessed, and performance and processing needs. Relational databases, on the other hand, were not designed to cope with the scale and agility challenges that face modern applications, nor were they built to take advantage of the cheap storage and processing power available today.
However most of the common database structures are not well suited to a block chain based database that aims to be as flexible as possible. We do not know in advance what data people may want to store on a block chain or how it should be indexed. A new approach is needed. I am going to blatantly copy a description of graph databases from Neo4j
Introducing Graph Databases
We live in a connected world. There are no isolated pieces of information, but rich, connected domains all around us. Only a database that embraces relationships as a core aspect of its data model is able to store, process, and query connections efficiently. While other databases compute relationships expensively at query time, a graph database stores connections as first level citizens, readily available for any “join-like” navigation operation. Accessing those already persistent connections is an efficient, constant-time operation and allows you to quickly traverse millions of connections per second.
Independent of the size of the total dataset, graph databases excel at managing highly connected data and complex queries. Armed only with a pattern and a set of starting points, graph databases explore the larger neighborhood around their initial points—collecting and aggregating information from millions of nodes and relationships—leaving the billions outside the search perimeter untouched.
The Property Graph Model
If you’ve ever worked with an object model or entity relationship diagram, the labeled property graph model will seem familiar. The property graph contains connected entities (the nodes) which can hold arbitrary types and numbers of properties (key-value-pairs). Nodes can be tagged with zero to many labels representing their different roles in the domain. In addition to contextualizing node and relationship properties, labels may also serve to attach metadata—index or constraint information, for example—to nodes.
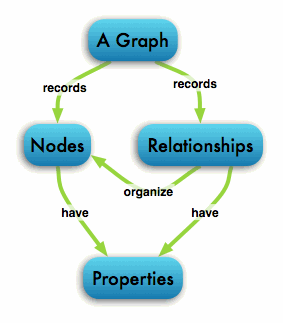 Relationships provide directed, named semantic connections between two nodes. A relationship always has a direction, a type, a start node, and an end node. Like nodes, relationships can have arbitrary properties. In most cases, relationships have quantitative properties, such as weights, distances, ratings, time intervals, or strengths. As relationships are stored efficiently, two nodes can have any number or type of relationships between them without sacrificing performance. Note that although they are directed, relationships can always be navigated in both directions.
Relationships provide directed, named semantic connections between two nodes. A relationship always has a direction, a type, a start node, and an end node. Like nodes, relationships can have arbitrary properties. In most cases, relationships have quantitative properties, such as weights, distances, ratings, time intervals, or strengths. As relationships are stored efficiently, two nodes can have any number or type of relationships between them without sacrificing performance. Note that although they are directed, relationships can always be navigated in both directions.
There is only one consistent rule in a graph database: “No broken links”. Since a relationship always has a start and end node, you can’t delete a node without also deleting its associated relationships. You can also always assume that an existing relationship will not point to a non-existing endpoint.
BitShares Graph Database
We are going to take the basic idea of a graph database and apply some relatively simple constraints. Every node (vertex/object) in the graph is managed by two multi-sig permissions, one for updating and one for transferring. Every edge in the graph is owned by its source node.
Edges are objects themselves. This means that you can construct an edge from a node to an edge or from an edge to an edge. On every object users can store arbitrary data as a JSON
object.
What this means is that the BitShares network becomes a general purpose graph database where the validation rules are simple. Interpretation of the database is entirely dependent upon client side applications. This provides great flexibility and allows the block chain to be kept simple. Some examples of things that we can implement with the Object Graph:
- Forum of linked Posts
- Web of Trust
- Identity Management
- Organization Membership
- Voting
- Domain Names
While all of those things are interesting, they are only scratching the surface of what people will come up with. In future posts I will explore some specific applications of the Object Graph. Here is a visual example from a traditional application:
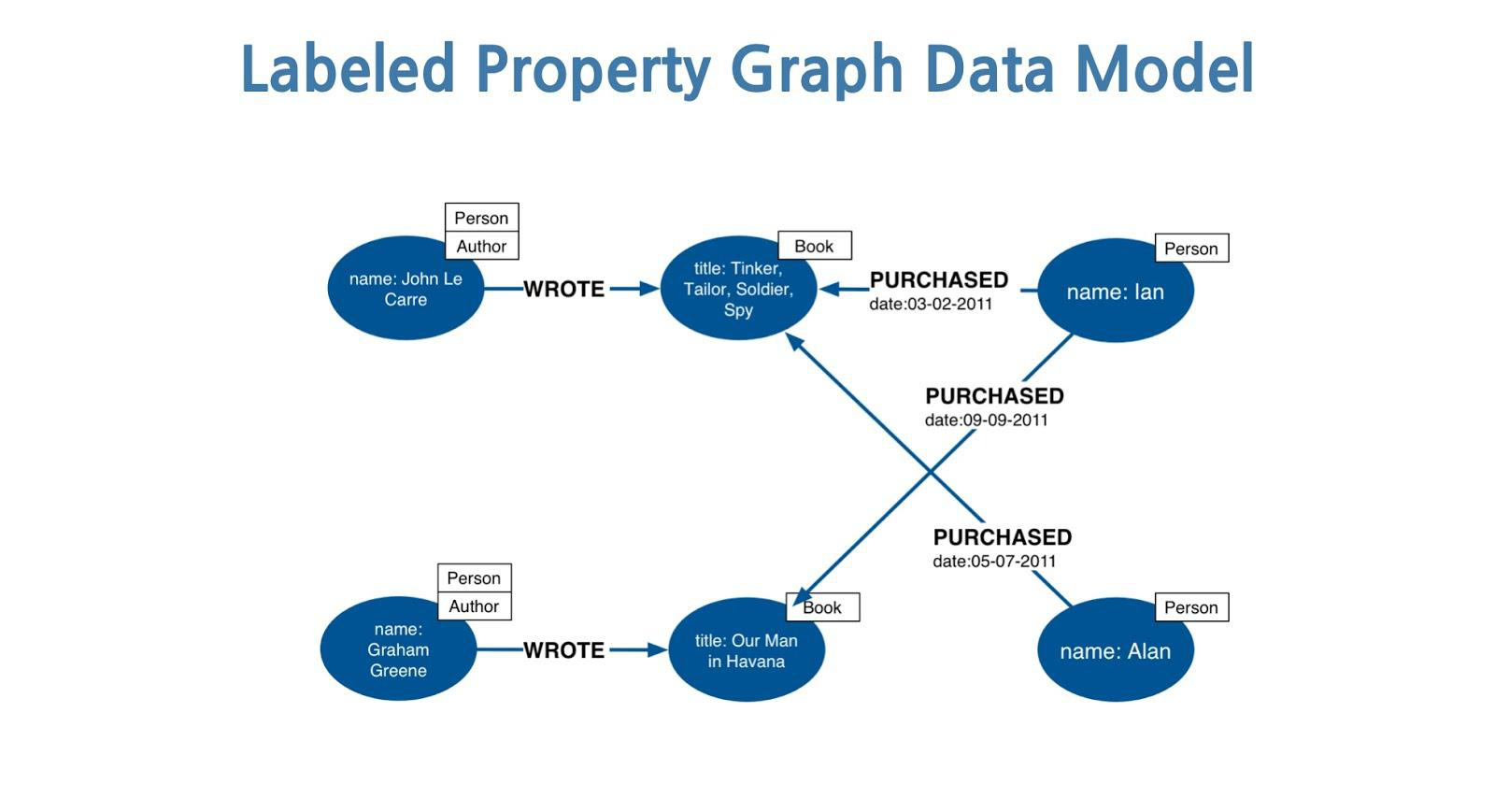
Accounts, Assets, Markets are First Class Objects
Every single item in the BitShares database will have a valid object ID and can be accessed via the graph API. This means that your user accounts and assets can become nodes in the wider graph and thus be the foundation of a web of trust.
Foundation for Scripting
The Object Graph will become the foundation for the future BitShares scripting environment. Every scripting language has a data model and this data model has a dramatic impact on the efficiency of scripting.
Ethereum has adopted a very simplistic database, a key-value store. A key-value store is a fundamental building block of all databases and is turing complete. By adopting a higher level data representation we can greatly accelerate many operations that would be expensive using a key-value store. It is like the difference between programing in assembly vs a higher level language like Java Script. We can optimize the graph database that the scripting environment runs on in ways that you would be unable to optimize a key-value store directly. In other words, Ethereum will force developers to build a graph database within their scripting environment on top of their key-value primitve. This will mean the graph database will be interpreted rather than fully optimized and compiled.
By building scripting environment on top of an object graph we can use better optimized data structures for performing lookups and reduce the number of operations that must be performed by the scripting environment itself. It becomes easier for developers to think about data and its relations rather than having to think about low-level primitives.
Status
The bitshares library already supports most of the operations necessary to create objects and link edges between them. We will be testing these features as part of DevShares in the weeks ahead before merging them into the BitShares network. If you have interesting ideas or applications for the BitShares Object Graph, please share them on our forum.
Recommended by Bytemaster
(see more...)








